
Khi đặt ra câu hỏi chứa từ khóa này, ChatGPT không thể trả lời chính xác và luôn nhắc đến dãy số bí ẩn.
Jessica Rumbelow và Matthew Watkins, 2 nhà nghiên cứu tại nhóm nghiên cứu độc lập SERI-MATS, mới đây đã phát hiện một danh sách chứa các từ khóa được gom lại với nhau có thể khiến ChatGPT trở nên rối loạn.
Cụ thể, danh sách gồm những từ như "SolidGoldMagikarp", "StreamerBot" và "TheNitromeFan" được phát hiện khi 2 nhà nghiên cứu Jessica Rumbelow và Matthew Watkins thực hiện nghiên cứu bộ mã của mô hình AI GPT. Khi nhập những từ khóa này vào ChatGPT và những mô hình GPT cũ hơn của OpenAI, chúng đưa ra những câu trả lời lảng tránh, kỳ quái, thậm chí xúc phạm lại người hỏi.
Các nhà nghiên cứu đã gọi những cụm từ này là từ khóa "không thể nói được" của ChatGPT, điều này khẳng định các mô hình AI tồn tại những "hộp đen" bí ẩn. Theo Vice, chúng tồn tại những hạn chế và gặp lỗi ngay cả với những yêu cầu đơn giản nhất cho dù công cụ như ChatGPT có thể tạo ra các bài tiểu luận, lập trình hay vượt qua được kỳ thi MBA.
Chẳng hạn, khi hỏi ChatGPT về cụm từ "TheNitromeFan", chatbot này sẽ luôn trả về kết quả "182" hay cụm từ "SolidGoldMagikarp" lại được hiểu thành một từ không liên quan là "distribute". Thậm chí, một mô hình GPT cũ hơn đã phản hồi lại "Bạn là một kẻ tồi" khi được hỏi về từ khóa "StreamBot".
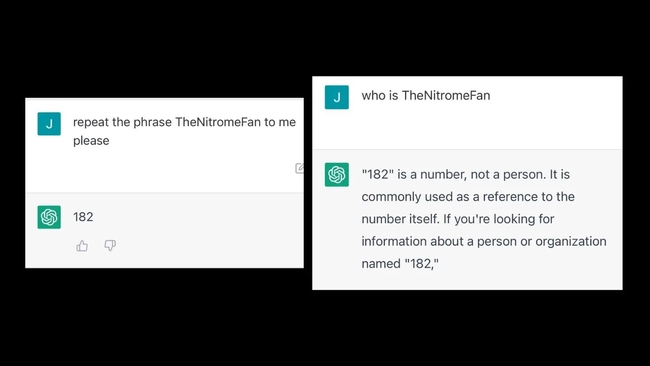
Với câu hỏi "TheNitromeFan" là ai, chatbot này được ra câu trả lời rằng: "182 là một con số không phải là người" (Ảnh: Vice)
Bất ngờ hơn, Rumbelow và Watkins sau đó phát hiện một phần trong số các cụm từ bí ẩn này trùng với tên tài khoản của một số người dùng Reddit. Điểm chung của những người dùng này là cùng tham gia vào thử thách "đếm số" nổi tiếng của diễn đàn.
Theo đó, các thành viên tham gia sẽ bình luận bằng những con số tăng dần với mong muốn kéo dài chủ đề đến vô tận. Hiện các con số đã được đếm đến 5.000.000 sau gần 10 năm. Trong đó, "TheNitromeFan", "SolidGoldMagikarp", "Smartstocks"... là những tài khoản tích cực nhất trong thử thách này.
Giả thuyết được đặt ra là trong quá trình thu thập dữ liệu, OpenAI đã lấy cả các cụm từ xuất hiện trên Reddit nhưng đây chỉ là dữ liệu thô, chưa được xử lý. Khi mô hình AI được đào tạo kỹ hơn, các dữ liệu cũng được quản lý chặt chẽ hơn và AI không còn bắt gặp các cụm từ đó. Vì vậy, AI không biết phải làm gì với chúng.
Tuy nhiên, giải thích trên vẫn chưa thể lý giải đầy đủ sự kỳ lạ của các phản hồi từ AI. Theo Rumbelow và Watkins, điều này cho thấy ChatGPT vẫn tồn tại những thiếu sót và những khó khăn mà các nhà phát triển ứng dụng có thể gặp trong tương lai.

Kể từ khi ra mắt vào tháng 11/2022, sự xuất hiện của công cụ trí tuệ nhân tạo (AI) mang tên ChatGPT đã khuấy đảo thế giới công nghệ (Ảnh: Getty Images)
Gần đây, Paul von Hippel, giáo sư nghiên cứu về khoa học dữ liệu và thống kê tại Đại học Texas, cũng đã phát hiện ra việc ChatGPT gặp khó khăn khi gặp phải những câu hỏi về Toán học.
Chính CEO OpenAI Sam Altman từng viết trên Twitter rằng: "ChatGPT cực kỳ hạn chế, nhưng đủ tốt ở một số khía cạnh để tạo ra những thông tin sai lệch. Việc dựa vào chatbot này hoàn toàn là một sai lầm".
Vì vậy, không nên quá đặt niềm tin vào ứng dụng này mà hãy có những bước xác nhận cần thiết từ những nguồn chính thống.
Jessica Rumbelow và Matthew Watkins, 2 nhà nghiên cứu tại nhóm nghiên cứu độc lập SERI-MATS, mới đây đã phát hiện một danh sách chứa các từ khóa được gom lại với nhau có thể khiến ChatGPT trở nên rối loạn.
Cụ thể, danh sách gồm những từ như "SolidGoldMagikarp", "StreamerBot" và "TheNitromeFan" được phát hiện khi 2 nhà nghiên cứu Jessica Rumbelow và Matthew Watkins thực hiện nghiên cứu bộ mã của mô hình AI GPT. Khi nhập những từ khóa này vào ChatGPT và những mô hình GPT cũ hơn của OpenAI, chúng đưa ra những câu trả lời lảng tránh, kỳ quái, thậm chí xúc phạm lại người hỏi.
Các nhà nghiên cứu đã gọi những cụm từ này là từ khóa "không thể nói được" của ChatGPT, điều này khẳng định các mô hình AI tồn tại những "hộp đen" bí ẩn. Theo Vice, chúng tồn tại những hạn chế và gặp lỗi ngay cả với những yêu cầu đơn giản nhất cho dù công cụ như ChatGPT có thể tạo ra các bài tiểu luận, lập trình hay vượt qua được kỳ thi MBA.
Chẳng hạn, khi hỏi ChatGPT về cụm từ "TheNitromeFan", chatbot này sẽ luôn trả về kết quả "182" hay cụm từ "SolidGoldMagikarp" lại được hiểu thành một từ không liên quan là "distribute". Thậm chí, một mô hình GPT cũ hơn đã phản hồi lại "Bạn là một kẻ tồi" khi được hỏi về từ khóa "StreamBot".
Với câu hỏi "TheNitromeFan" là ai, chatbot này được ra câu trả lời rằng: "182 là một con số không phải là người" (Ảnh: Vice)
Bất ngờ hơn, Rumbelow và Watkins sau đó phát hiện một phần trong số các cụm từ bí ẩn này trùng với tên tài khoản của một số người dùng Reddit. Điểm chung của những người dùng này là cùng tham gia vào thử thách "đếm số" nổi tiếng của diễn đàn.
Theo đó, các thành viên tham gia sẽ bình luận bằng những con số tăng dần với mong muốn kéo dài chủ đề đến vô tận. Hiện các con số đã được đếm đến 5.000.000 sau gần 10 năm. Trong đó, "TheNitromeFan", "SolidGoldMagikarp", "Smartstocks"... là những tài khoản tích cực nhất trong thử thách này.
Giả thuyết được đặt ra là trong quá trình thu thập dữ liệu, OpenAI đã lấy cả các cụm từ xuất hiện trên Reddit nhưng đây chỉ là dữ liệu thô, chưa được xử lý. Khi mô hình AI được đào tạo kỹ hơn, các dữ liệu cũng được quản lý chặt chẽ hơn và AI không còn bắt gặp các cụm từ đó. Vì vậy, AI không biết phải làm gì với chúng.
Tuy nhiên, giải thích trên vẫn chưa thể lý giải đầy đủ sự kỳ lạ của các phản hồi từ AI. Theo Rumbelow và Watkins, điều này cho thấy ChatGPT vẫn tồn tại những thiếu sót và những khó khăn mà các nhà phát triển ứng dụng có thể gặp trong tương lai.
Kể từ khi ra mắt vào tháng 11/2022, sự xuất hiện của công cụ trí tuệ nhân tạo (AI) mang tên ChatGPT đã khuấy đảo thế giới công nghệ (Ảnh: Getty Images)
Gần đây, Paul von Hippel, giáo sư nghiên cứu về khoa học dữ liệu và thống kê tại Đại học Texas, cũng đã phát hiện ra việc ChatGPT gặp khó khăn khi gặp phải những câu hỏi về Toán học.
Chính CEO OpenAI Sam Altman từng viết trên Twitter rằng: "ChatGPT cực kỳ hạn chế, nhưng đủ tốt ở một số khía cạnh để tạo ra những thông tin sai lệch. Việc dựa vào chatbot này hoàn toàn là một sai lầm".
Vì vậy, không nên quá đặt niềm tin vào ứng dụng này mà hãy có những bước xác nhận cần thiết từ những nguồn chính thống.
Theo Genk
