
Chinh phục công nghệ trí tuệ nhân tạo vẫn là một thách thức khó nhằn. Nhưng mới đây, các hãng IBM, Nvidia và các nhà nghiên cứu đã có một giải pháp “điên rồ” giúp những người làm việc về máy học có thể dễ thở hơn một chút: kết nối trực tiếp giữa GPU với SSD.
Trong một nghiên cứu mới được công bố, ý tưởng này được gọi là Big accelerator Memory (BaM) và liên quan đến việc kết nối trực tiếp GPU tới một lượng lớn ổ cứng SSD. Điều này giúp giải quyết điểm nghẽn trong tác vụ huấn luyện máy học và các tác vụ chuyên sâu khác.
Trong nghiên cứu của mình, các nhà khoa học cho biết: “BaM giảm thiểu sự khuếch đại băng thông vào ra (I/O) bằng cách cho phép các luồng GPU đọc hoặc viết một lượng nhỏ dữ liệu theo yêu cầu, như những gì máy tính xác định trước.”

Tăng tốc xử lý và độ ổn định
“Mục đích của BaM là mở rộng dung lượng bộ nhớ GPU và tăng cường băng thông truy cập bộ nhớ lưu trữ trong khi cung cấp khả năng trừu tượng hóa mức độ cao cho các luồng GPU để dễ dàng truy cập theo yêu cầu, một cách chi tiết tới các cấu trúc dữ liệu khổng lồ trong hệ thống phân cấp bộ nhớ.”
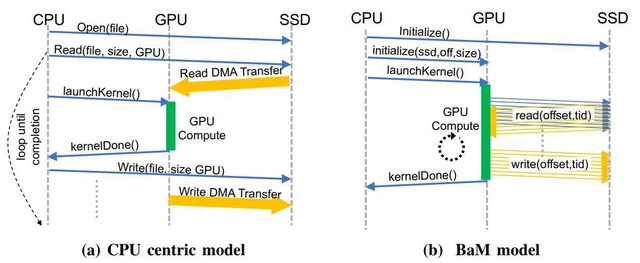
So sánh giữa thiết kế với CPU làm trung tâm và thiết kế mới của BaM
Mục đích cuối cùng là nhằm giảm sự phụ thuộc vào các GPU Nvidia vào phần cứng tăng tốc xử lý dành cho các CPU đa dụng. Thông thường CPU sẽ là trung tâm xử lý các tác vụ, bao gồm mở file, đọc file từ SSD, gửi dữ liệu tới GPU, khởi động GPU để xử lý và trả kết quả về CPU rồi sau đó mới gửi tới SSD.
Với BaM, GPU mới là trung tâm khi trực tiếp lấy dữ liệu về và xử lý thay vì phụ thuộc vào CPU. Nhờ có băng thông và tốc độ truy cập dữ liệu lớn hơn cùng với việc có nhiều luồng xử lý hơn, khả năng tính toán của GPU sẽ được cải thiện đáng kể so với thiết kế cũ. Bằng cách cho phép các GPU Nvidia kết nối trực tiếp vào bộ nhớ lưu trữ và sau đó xử lý dữ liệu, giải pháp này đang được triển khai trên nhiều công cụ chuyên dụng nhất hiện nay.
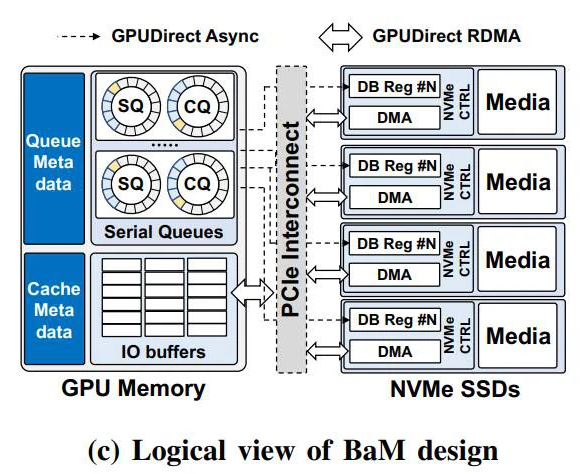
Nhưng làm thế nào các GPU này có thể truy cập dữ liệu mà không cần đến sự hỗ trợ từ các CPU? Về lý thuyết, BaM sử dụng một bộ nhớ đệm của GPU được quản lý bởi phần mềm bên cạnh một thư viện, nơi các luồng GPU có thể truy vấn dữ liệu trực tiếp trên các SSD NVMe. Việc di chuyển thông tin giữa chúng với nhau được xử lý bởi các GPU.
Cuối cùng, giải pháp này sẽ giúp các tác vụ máy học và nhiều tác vụ chuyên sâu khác có thể truy cập dữ liệu nhanh chóng hơn và quan trọng hơn, theo những cách cụ thể để giúp ích cho các tải công việc khối lượng lớn. Trong các thử nghiệm của mình, giải pháp này đã chứng minh tính hiệu quả khi GPU và SSD hoạt động tốt, tốc độ truyền và xử lý dữ liệu đã nhanh hơn đáng kể trước đây.
Hiện tại, nhóm nghiên cứu đang dự định mã nguồn mở thiết kế phần cứng và phần mềm của mình để giúp ích nhiều hơn cho cộng đồng nghiên cứu máy học trên thế giới.
Trong một nghiên cứu mới được công bố, ý tưởng này được gọi là Big accelerator Memory (BaM) và liên quan đến việc kết nối trực tiếp GPU tới một lượng lớn ổ cứng SSD. Điều này giúp giải quyết điểm nghẽn trong tác vụ huấn luyện máy học và các tác vụ chuyên sâu khác.
Trong nghiên cứu của mình, các nhà khoa học cho biết: “BaM giảm thiểu sự khuếch đại băng thông vào ra (I/O) bằng cách cho phép các luồng GPU đọc hoặc viết một lượng nhỏ dữ liệu theo yêu cầu, như những gì máy tính xác định trước.”

Tăng tốc xử lý và độ ổn định
“Mục đích của BaM là mở rộng dung lượng bộ nhớ GPU và tăng cường băng thông truy cập bộ nhớ lưu trữ trong khi cung cấp khả năng trừu tượng hóa mức độ cao cho các luồng GPU để dễ dàng truy cập theo yêu cầu, một cách chi tiết tới các cấu trúc dữ liệu khổng lồ trong hệ thống phân cấp bộ nhớ.”

So sánh giữa thiết kế với CPU làm trung tâm và thiết kế mới của BaM
Mục đích cuối cùng là nhằm giảm sự phụ thuộc vào các GPU Nvidia vào phần cứng tăng tốc xử lý dành cho các CPU đa dụng. Thông thường CPU sẽ là trung tâm xử lý các tác vụ, bao gồm mở file, đọc file từ SSD, gửi dữ liệu tới GPU, khởi động GPU để xử lý và trả kết quả về CPU rồi sau đó mới gửi tới SSD.
Với BaM, GPU mới là trung tâm khi trực tiếp lấy dữ liệu về và xử lý thay vì phụ thuộc vào CPU. Nhờ có băng thông và tốc độ truy cập dữ liệu lớn hơn cùng với việc có nhiều luồng xử lý hơn, khả năng tính toán của GPU sẽ được cải thiện đáng kể so với thiết kế cũ. Bằng cách cho phép các GPU Nvidia kết nối trực tiếp vào bộ nhớ lưu trữ và sau đó xử lý dữ liệu, giải pháp này đang được triển khai trên nhiều công cụ chuyên dụng nhất hiện nay.
Nhưng làm thế nào các GPU này có thể truy cập dữ liệu mà không cần đến sự hỗ trợ từ các CPU? Về lý thuyết, BaM sử dụng một bộ nhớ đệm của GPU được quản lý bởi phần mềm bên cạnh một thư viện, nơi các luồng GPU có thể truy vấn dữ liệu trực tiếp trên các SSD NVMe. Việc di chuyển thông tin giữa chúng với nhau được xử lý bởi các GPU.
Cuối cùng, giải pháp này sẽ giúp các tác vụ máy học và nhiều tác vụ chuyên sâu khác có thể truy cập dữ liệu nhanh chóng hơn và quan trọng hơn, theo những cách cụ thể để giúp ích cho các tải công việc khối lượng lớn. Trong các thử nghiệm của mình, giải pháp này đã chứng minh tính hiệu quả khi GPU và SSD hoạt động tốt, tốc độ truyền và xử lý dữ liệu đã nhanh hơn đáng kể trước đây.
Hiện tại, nhóm nghiên cứu đang dự định mã nguồn mở thiết kế phần cứng và phần mềm của mình để giúp ích nhiều hơn cho cộng đồng nghiên cứu máy học trên thế giới.
Theo Genk
